Word Embeddings
Training Embeddings
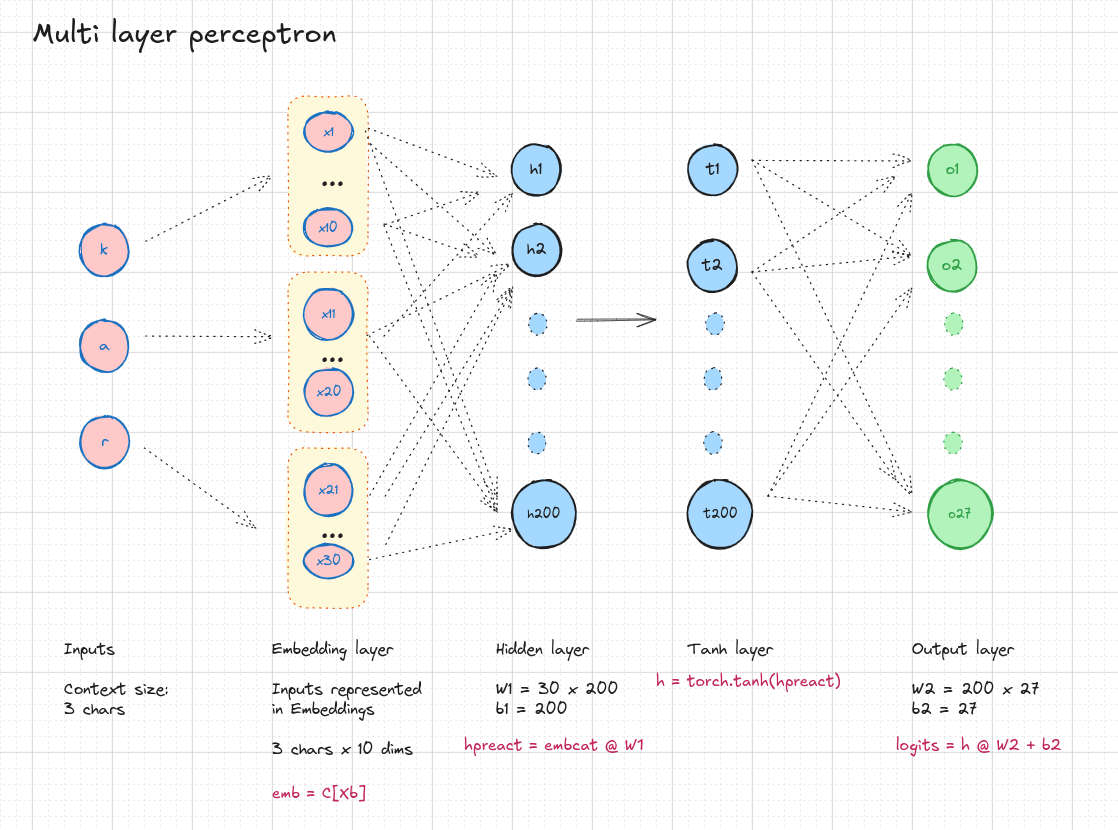
In Building makemore Part 2: MLP, Karpathy trains a character-level model by feeding X-characters as input (3 chars), and each character is represented as a N dimensional vector (2 dim) in the example. Initially, the Embedding layer C (It is 27 x 2 matrix) is initialised with random values. After training for some epochs, the embeddings are trained.
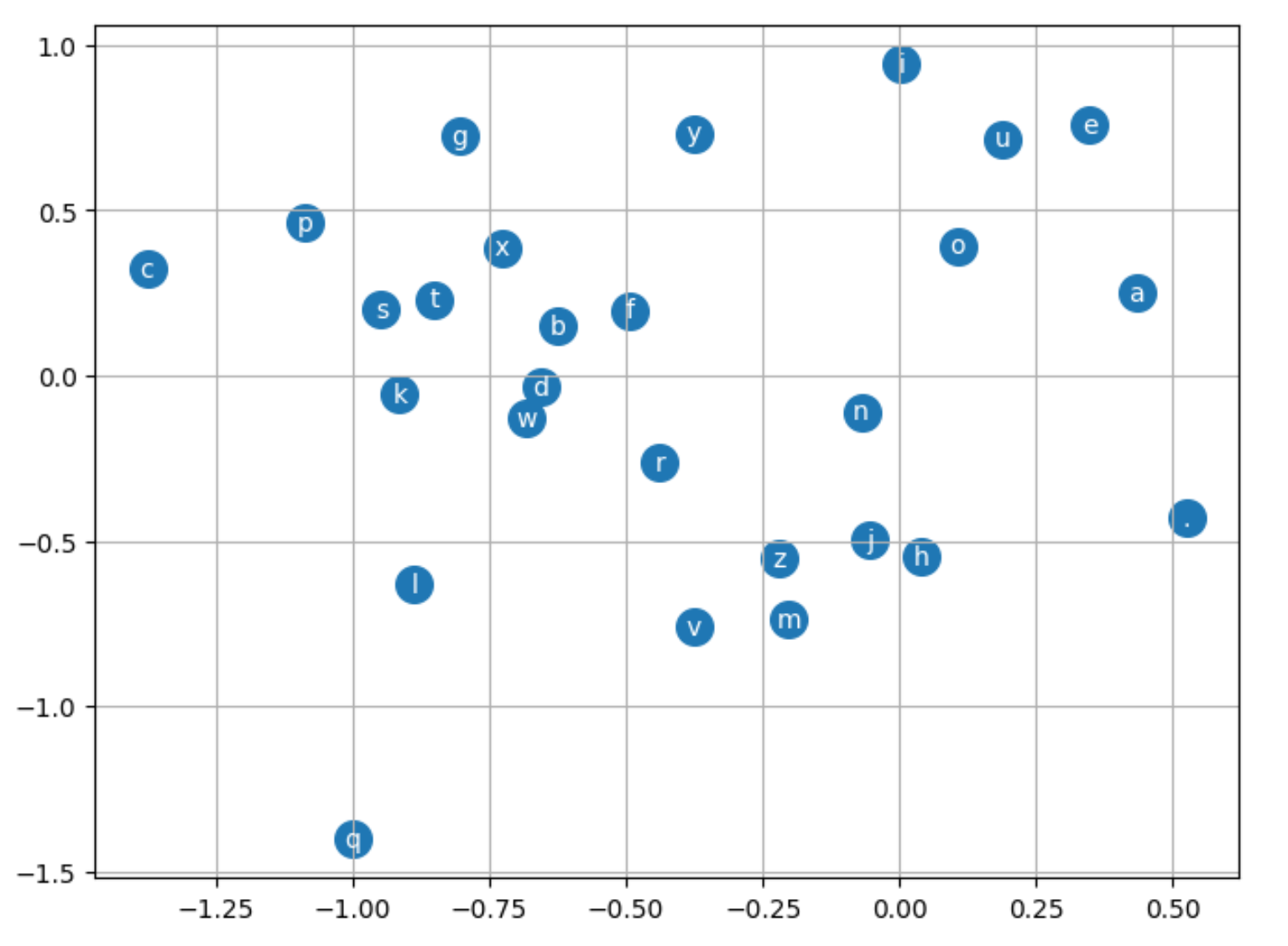
Plotting the embeddings
Since the embeddings dimensions are 2, it is easy to visualise them.
Here, all the vowels are kind of together, Other chars are a bit away. So now, the model knows that a, e, i, o, u are vowels and different from other characters somehow?
I would like to train word embeddings with large text and would like to see whether King, Queen, Prince, Princess are near by !!
The embedding matrix is below for 27 chars (. and a to z):
tensor([[ 0.5259, -0.4311],
[ 0.4329, 0.2509],
[-0.6244, 0.1519],
[-1.3756, 0.3216],
[-0.6550, -0.0351],
[ 0.3465, 0.7587],
[-0.4946, 0.1976],
[-0.8055, 0.7258],
[ 0.0408, -0.5462],
[ 0.0039, 0.9416],
[-0.0549, -0.4981],
[-0.9140, -0.0582],
[-0.8874, -0.6310],
[-0.2022, -0.7367],
[-0.0698, -0.1096],
[ 0.1065, 0.3930],
[-1.0866, 0.4625],
[-0.9991, -1.4025],
[-0.4381, -0.2614],
[-0.9473, 0.1994],
[-0.8495, 0.2304],
[ 0.1884, 0.7167],
[-0.3770, -0.7586],
[-0.6825, -0.1296],
[-0.7267, 0.3870],
[-0.3765, 0.7330],
[-0.2203, -0.5527]], requires_grad=True)
# View embeddings
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(8, 6))
plt.scatter(C[:, 0].data, C[:, 1].data, s=200)
for i in range(C.shape[0]):
plt.text(C[i, 0].item(), C[i, 1].item(), itos[i], ha="center", va="center", color="white")
plt.grid()