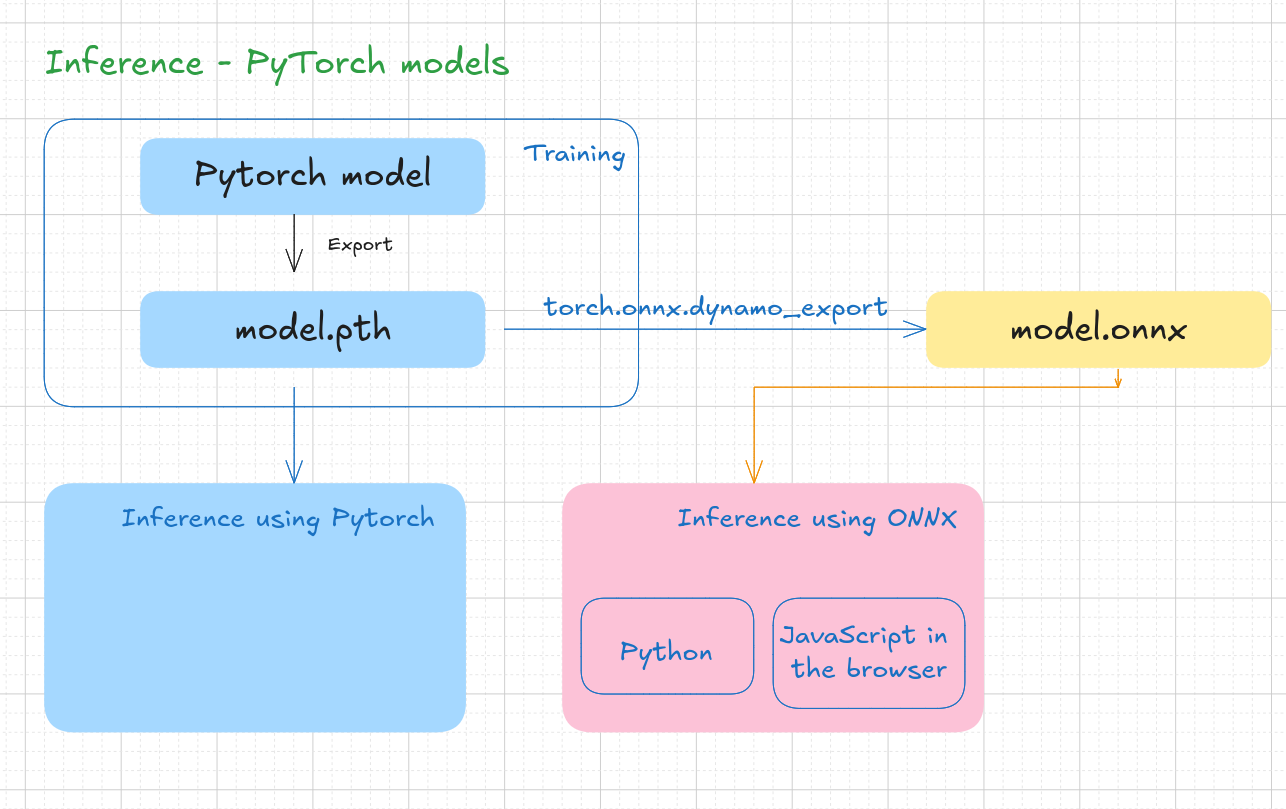
Inference-pytorch-models
About
Somehow I like the idea of running ML models in the browser. After having seen some demos, and transformer explainer I thought of learning the end to end process to achieve this. I have some idea about using PyTorch models. I got to know about ONNX (ONNX is an open format built to represent machine learning models. ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers.).
[makemore](# Building makemore Part 5: Building a WaveNet) is a character level neural network written in PyTorch generates names. I thought of using this model to convert this to ONNX format and run in browser. This page talks my experiences.
PyTorch to ONNX
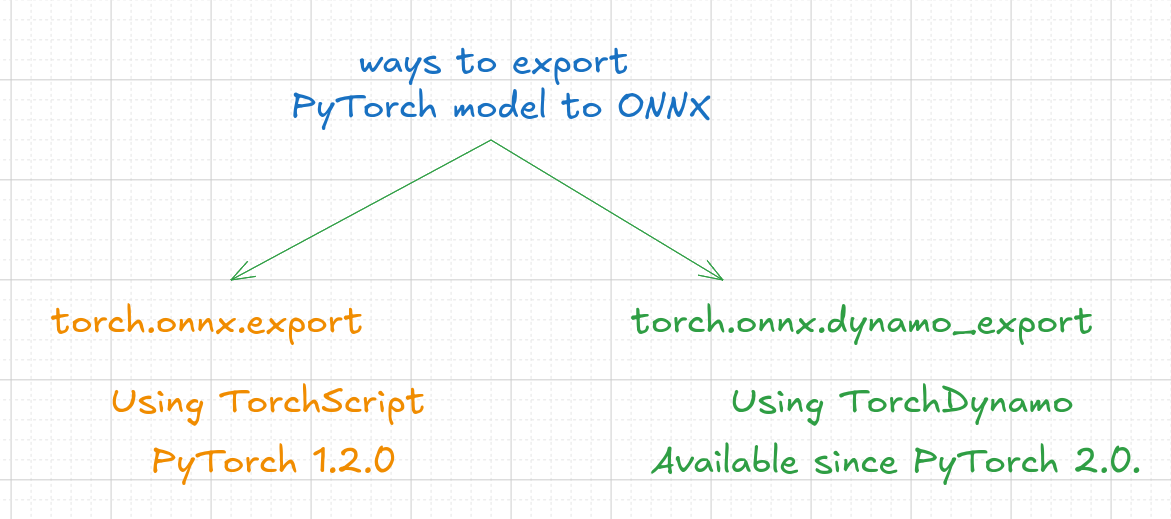
Since dynamo_export is latest, I opted to use it.
Train the model
python makemore_1_train_model.py
...
Parameters in each layer
------------------------------------------------------------------------------------------------------------------------
1 Embedding : Shape: torch.Size([27, 24]) Parameters: 648 Gradient: Enabled
2 Linear : Shape: torch.Size([128, 48]) Parameters: 6144 Gradient: Enabled
3 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
3 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
4 Linear : Shape: torch.Size([128, 256]) Parameters: 32768 Gradient: Enabled
5 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
5 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
6 Linear : Shape: torch.Size([128, 256]) Parameters: 32768 Gradient: Enabled
7 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
7 BatchNorm1d : Shape: torch.Size([128]) Parameters: 128 Gradient: Enabled
8 Linear : Shape: torch.Size([27, 128]) Parameters: 3456 Gradient: Enabled
8 Linear : Shape: torch.Size([27]) Parameters: 27 Gradient: Enabled
Total parameters: 76579
Torch CUDA available? True
Epoch: 001/050 | Train Batch Loss: 2.4175
Epoch: 002/050 | Train Batch Loss: 1.9685
Epoch: 003/050 | Train Batch Loss: 2.1298
...
oss on training set: 1.9991798400878906
Loss on validation set: 2.2351705763075085
Loss on test set: 1.9602480242329259
Model saved to ./models/makemore_model.pth
The model is saved using:
...
# Save the model
model_path = "./models/makemore_model.pth"
torch.save(model, model_path)
print(f"\nModel saved to {model_path}")
Inference using saved weights
...
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load("./models/makemore_model.pth")
model.eval()
model = model.to(device)
...
- Model is loaded using
torch.load() - It is set to
evalmode.
$ python python makemore_2_inference.py
['dmarior', 'noel', 'elisabett', 'garden', 'liana', 'ilaan', 'aquarin', 'tylon', 'ranira', 'levih', 'sanda', 'ciel', 'anyela', 'bulbry', 'merlyn', 'zaydon', 'teagan', 'beatris', 'prosper', 'desi']
Export the model to ONNX format
"""
This script exports the makemore model to ONNX format.
Ref:
https://pytorch.org/docs/stable/onnx_dynamo.html#a-simple-example
"""
import os.path
import onnx
import onnxruntime
import torch
def to_numpy(tensor):
return (
tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
)
def print_nodes():
model = onnx.load(onnx_model)
# Print out all the nodes in the model
for node in model.graph.node:
print(f"Node: {node.name}, Op Type: {node.op_type}")
for input in node.input:
print(f" Input: {input}")
for output in node.output:
print(f" Output: {output}")
print()
def verify_onnx_file():
model = onnx.load(onnx_model)
# Check that the model is well-formed
onnx.checker.check_model(model)
# Print a human-readable representation of the graph
print(onnx.helper.printable_graph(model.graph))
def inspect_onnx_model(model_path):
# Load the ONNX model
model = onnx.load(model_path)
print("Model inputs:")
for input in model.graph.input:
print(f" Name: {input.name}")
print(f" Shape: {[dim.dim_value for dim in input.type.tensor_type.shape.dim]}")
print(f" Type: {input.type.tensor_type.elem_type}")
print()
print("Model outputs:")
for output in model.graph.output:
print(f" Name: {output.name}")
print(
f" Shape: {[dim.dim_value for dim in output.type.tensor_type.shape.dim]}"
)
print(f" Type: {output.type.tensor_type.elem_type}")
print()
print("Model operations:")
for i, node in enumerate(model.graph.node):
print(f"Node {i}:")
print(f" Op Type: {node.op_type}")
print(f" Name: {node.name}")
print(f" Inputs: {node.input}")
print(f" Outputs: {node.output}")
# If it's a Gemm operation, let's check its attributes
if node.op_type == "Gemm":
print(" Gemm Attributes:")
for attr in node.attribute:
print(
f" {attr.name}: {attr.i if attr.type == onnx.AttributeProto.INT else attr.f}"
)
print()
# Check for initializers (weights and biases)
print("Model initializers:")
for initializer in model.graph.initializer:
print(f" Name: {initializer.name}")
print(f" Shape: {initializer.dims}")
print(f" Data type: {initializer.data_type}")
# Uncomment the next line if you want to see the actual values
# print(f" Values: {numpy_helper.to_array(initializer)}") print()
models_location = "./models"
pytorch_model = os.path.join(models_location, "makemore_model.pth")
onnx_model = os.path.join(models_location, "makemore.onnx")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. Load PyTorch model
model = torch.load(pytorch_model, weights_only=False)
model = model.to(device)
model.eval()
# 2. Export the model to ONNX format
context = [0] * 8
torch_input = torch.tensor([context])
onnx_program = torch.onnx.dynamo_export(model, torch_input)
onnx_program.save(onnx_model)
print(f"Model exported to ONNX format: {onnx_model}")
print("\nNodes")
print("-" * 100)
print_nodes()
print("\nGraph")
print("-" * 100)
verify_onnx_file()
print("\nInputs, Outputs, Operations, Initializers")
print("-" * 100)
inspect_onnx_model(onnx_model)
# 3. Test the ONNX model with ONNX Runtime
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(torch_input)
print(f"Input length: {len(onnx_input)}")
print(f"Sample input to the model: {onnx_input}")
ort_session = onnxruntime.InferenceSession(
onnx_model, providers=["CPUExecutionProvider"]
)
onnxruntime_input = {
k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)
}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
print(f"Output from the model: {onnxruntime_outputs}")
python makemore_3_export_to_onnx_dynamo.py
/.venv/lib/python3.11/site-packages/torch/onnx/_internal/exporter.py:130: UserWarning: torch.onnx.dynamo_export only implements opset version 18 for now. If you need to use a different opset version, please register them with register_custom_op.
warnings.warn(
/.venv/lib/python3.11/site-packages/torch/onnx/_internal/fx/passes/readability.py:53: UserWarning: Attempted to insert a get_attr Node with no underlying reference in the owning GraphModule! Call GraphModule.add_submodule to add the necessary submodule, GraphModule.add_parameter to add the necessary Parameter, or nn.Module.register_buffer to add the necessary buffer
new_node = self.module.graph.get_attr(normalized_name)
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_3_bn_running_mean target all_layers/3/bn/running_mean all_layers/3/bn/running_mean of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_3_bn_running_var target all_layers/3/bn/running_var all_layers/3/bn/running_var of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_7_bn_running_mean target all_layers/7/bn/running_mean all_layers/7/bn/running_mean of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_7_bn_running_var target all_layers/7/bn/running_var all_layers/7/bn/running_var of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_11_running_mean target all_layers/11/running_mean all_layers/11/running_mean of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
/.venv/lib/python3.11/site-packages/torch/fx/graph.py:1377: UserWarning: Node all_layers_11_running_var target all_layers/11/running_var all_layers/11/running_var of does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(f'Node {node} target {node.target} {atom} of {seen_qualname} does '
Model exported to ONNX format: ./models/makemore.onnx
Node: torch_nn_modules_container_Sequential_all_layers_1_0, Op Type: torch_nn_modules_container_Sequential_all_layers_1
Input: arg0
Input: all_layers.0.weight
Input: all_layers.2.weight
Input: all_layers.3.bn.weight
Input: all_layers.3.bn.bias
Input: all_layers.3.bn.running_mean
Input: all_layers.3.bn.running_var
Input: all_layers.6.weight
Input: all_layers.7.bn.weight
Input: all_layers.7.bn.bias
Input: all_layers.7.bn.running_mean
Input: all_layers.7.bn.running_var
Input: all_layers.10.weight
Input: all_layers.11.weight
Input: all_layers.11.bias
Input: all_layers.11.running_mean
Input: all_layers.11.running_var
Input: all_layers.13.weight
Input: all_layers.13.bias
Output: all_layers_1
Input length: 1
Sample input: (tensor([[0, 0, 0, 0, 0, 0, 0, 0]]),)
[array([[-11.209396 , 2.16014 , 0.95827687, 1.2020378 ,
1.0899217 , 0.89327663, -0.19877136, 0.40375108,
0.43734524, 0.19997144, 1.5035927 , 1.6288222 ,
0.98608905, 1.515521 , 0.68121505, -0.59675086,
-0.03565785, -1.8668526 , 1.3594905 , 1.2657825 ,
0.8238262 , -2.3166988 , -0.47821325, -0.3949 ,
-1.2404733 , -0.0304848 , 0.53811175]], dtype=float32)]
Sizes of the weights
-rw-rw-r-- 1 rk rk 320902 Aug 12 13:21 makemore_model.pth
-rw-rw-r-- 1 rk rk 337303 Aug 12 13:29 makemore.onnx
Inference using ONNX - Python runtime
"""
Inferring from the ONNX model
Ref:
https://pytorch.org/docs/stable/onnx_dynamo.html#a-simple-example
"""
import os
import onnxruntime as ort
import torch
import torch.nn.functional as F
models_location = "./models"
onnx_model = os.path.join(models_location, "makemore.onnx")
ort_session = ort.InferenceSession(onnx_model)
names = list()
itos = {
0: ".",
1: "a",
2: "b",
3: "c",
4: "d",
5: "e",
6: "f",
7: "g",
8: "h",
9: "i",
10: "j",
11: "k",
12: "l",
13: "m",
14: "n",
15: "o",
16: "p",
17: "q",
18: "r",
19: "s",
20: "t",
21: "u",
22: "v",
23: "w",
24: "x",
25: "y",
26: "z",
}
for _ in range(5):
out = []
context = [0] * 8 # initialize with all ...
while True:
torch_input = torch.tensor([context])
onnxruntime_input = {ort_session.get_inputs()[0].name: torch_input.numpy()}
ort_outs = ort_session.run(None, onnxruntime_input)
logits = ort_outs[0]
probs = F.softmax(torch.tensor(logits), dim=1)
# Sample from the distribution
ix = torch.multinomial(probs, num_samples=1).item()
# shift the context window and track the samples
context = context[1:] + [ix]
# If special token, break
if ix == 0:
break
else:
out.append(ix)
names.append("".join(itos[i] for i in out))
print(names)
python makemore_4_inference_onnx.py
['dmilany', 'addisyn', 'redicka', 'ellin', 'pheham']
Using the ONNX Model in web browser
I started with this - https://github.com/ryandam9/makemore/blob/master/inference-in-browser/base.html. I realized I need explore some docs about web runtime. I will revisit this.